













 AI智能应用开发(Java)
AI智能应用开发(Java) 鸿蒙应用开发
鸿蒙应用开发 HTML&JS+前端
HTML&JS+前端 Python+大数据开发
Python+大数据开发 人工智能开发
人工智能开发 跨境电商
跨境电商 电商视觉设计
电商视觉设计 软件测试
软件测试 新媒体+短视频
新媒体+短视频 集成电路应用开发
集成电路应用开发 C/C++
C/C++ 狂野架构师
狂野架构师 IP短视频
IP短视频


全部 Python+大数据新闻动态 Python+大数据技术文章 Python+大数据学习常见问题 技术问答
-
-

MySQL表数据导入到Hive文件【图文详解】
如果Hadoop集群中部署了Hive服务,并且在Sqoop服务的sqoop-env.sh文件中配置了Hive的安装路径,那么也可以通过Sqoop工具将MySQL表数据导入Hive表中。将MySQL表数据导入到Hive文件系统中,具体指令示例如下。 查看全文>>
Python+大数据技术文章2021-08-06 |传智教育 |MySQL表数据导入Hive
-

Pandas算术运算和数据对齐【Pandas索引操作演示】
Pandas执行算术运算时,会先按照索引进行对齐,对齐以后再进行相应的运算,没有对齐的位置会用NaN进行补齐。其中,Series是按行索引对齐的,DataFrame是按行索引、列索引对齐的。 查看全文>>
Python+大数据技术文章2021-07-30 |传智教育 |Panda,算术运算和数据对齐
-
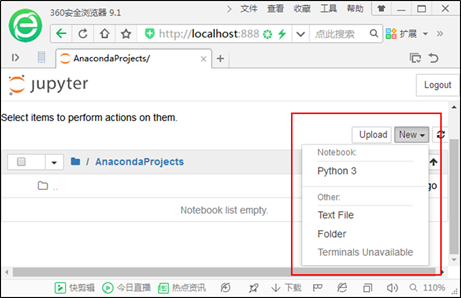
Jupyter Notebook功能和操作界面介绍
在Jupyter Notebook的主界面中,单击 “Anaconda Projects” 进入该目录下,继续单击右上方的“New”按钮,打开如图1所示的下拉列表。 查看全文>>
Python+大数据技术文章2021-07-30 |传智教育 |Notebook功能和操作界面介绍, Jupyter
-

-

数据仓库一般分为几层?数据仓库实际分层介绍
这里我们采用的是京东的数据仓库分层模式,是根据标准的模型演化而来。将数据仓库分为4层,BDM作为缓冲数据,FDM作为基础数据层,接下来对他们做详细介绍。 查看全文>>
Python+大数据技术文章2021-07-28 |传智教育 |数据仓库,数据仓库实际分层
-
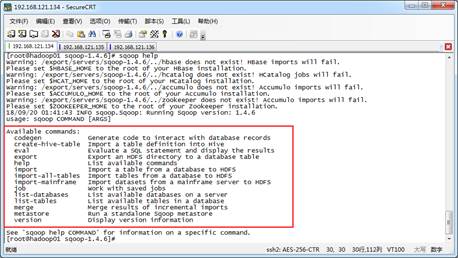
Sqoop有哪些指令?Sqoop指令介绍
Sqoop工具操作简单,它提供了一系列的工具指令,来进行数据的导入、导出操作等。使用Sqoop解压包中bin目录下的“sqoop help”指令可以查看Sqoop支持的所有工具指令,具体效果如图1所示。 查看全文>>
Python+大数据技术文章2021-07-26 |传智教育 |Sqoop,sqoop指令
-

手把手教你搭建Hadoop高可用集群
掌握了Hadoop集群中的高可用架构后,接下来,我们来手把手教大家搭建一个Hadoop高可用集群,具体步骤如下: 查看全文>>
Python+大数据技术文章2021-07-26 |传智教育 |高可用集群,高可用架构,Hadoop
-

Zookeeper数据发布与订阅主要应用场景有哪些?
数据发布与订阅模型,即所谓的全局配置中心,顾名思义就是发布者将需要全局统一管理的数据发布到Zookeeper节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息,服务式服务框架的服务地址列表等就非常适合使用。接下来,我们介绍一些数据发布与订阅的主要应用场景。 查看全文>>
Python+大数据技术文章2021-07-26 |传智教育 |数据发布与订阅的应用场景,zookeeper,
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All Rights Reserved 苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号